Cloudflare accused AI of conquering the use of “Secret Searching” to avoid bans, rotate IP addresses, and imitate conventional browsers to access blocked websites.
Cloudflare eliminated the confusion of his program of proven robots and deployed new technical defense to capture and block deceptive scratches.
The confusion denies the demands and calls evidence of cloudflare a “sales playground” and challenges that any prohibited content has been accessible.
According to Cloudflare Internet Infrastructure Provider, Spartexity continued to access the content of tens of thousands of websites even after this site explicitly blocked them. The company said on Monday to eliminate the confusion of its proven shoe program and implemented blocks against what it characterized as misleading scratches.
The mass based in San Francisco was founded in 2022 by Aravind Srinivas (CEO, former researcher Openai), Denis Yarats (former Facebook AI), Johnny Ho and Andy Konwinski (Databricks). The company received funds from investors including Elada Gil, Nat Friedman (former CEO of GitHub) and NVIDIA, among other things and was awarded at $ 18 billion After getting last month $ 100 million.
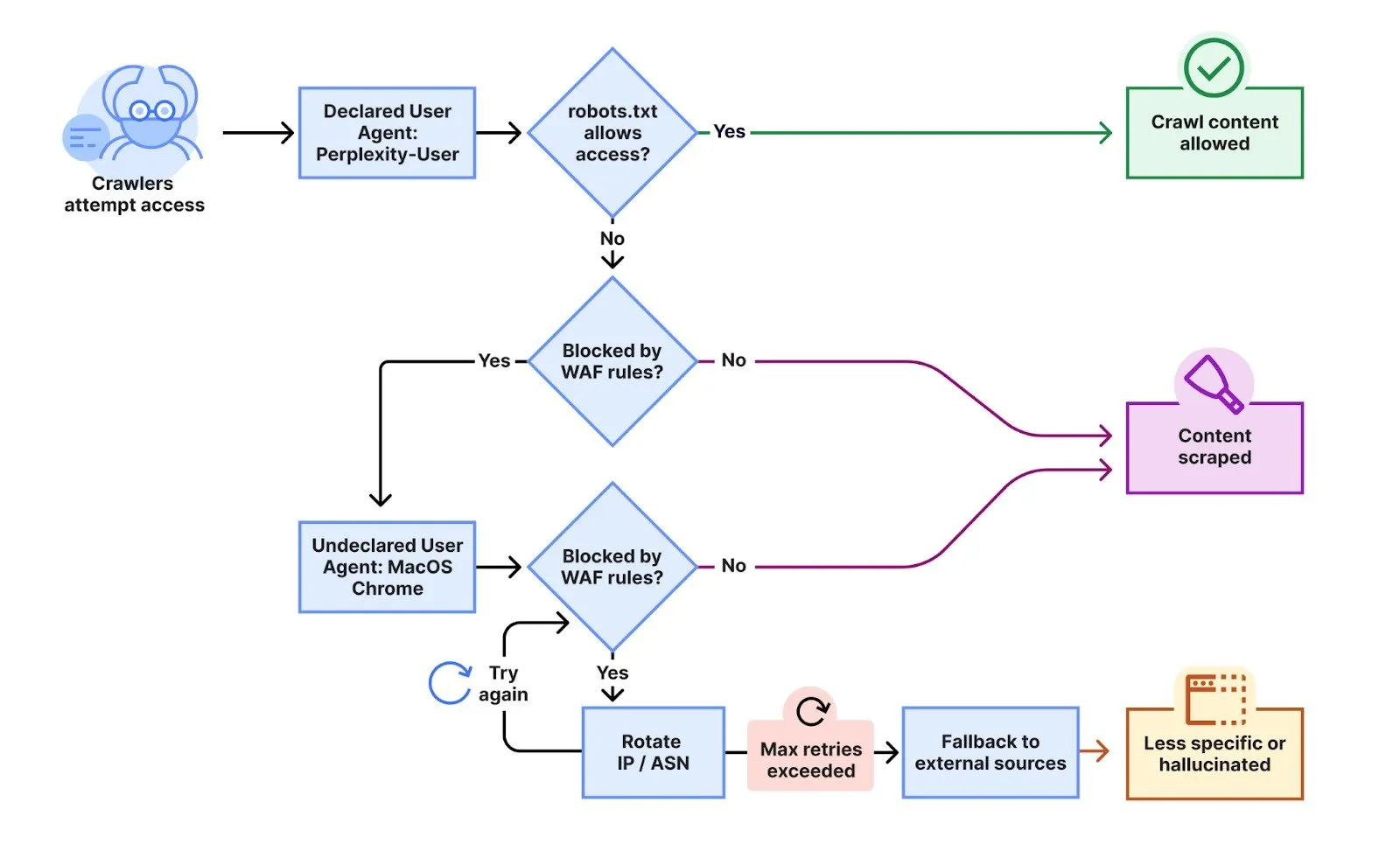
A recent conflict broke out after customers have complained that confusion was still scratching their site, despite the implementation of both robots. TXT Directives and specific firewall rules to block AI’s declared search engines. Cloudflare engineers Gabriel Corral, Vaibhav Singhal, Brian Mitchell and Reid Tatoris confirmed in tests that “search engines were actually blocked on specific pages.
To test the behavior of confusion, Cloudflare created several newly purchased domains with restrictive robots.txt files that banned all automated access. “We conducted an experiment by questioning AI confusion with questions about these domains, and the discovered confusion still provided detailed information about the exact content hosted in each of these limited domains.”
What happened was surprised. Rather than respecting blocks, confusion seemed to switch tactics. “We have found that confusion uses not only their declared user agent, but also a general browser designed to release Google Chrome on MacOS when their declared climbing frame is blocked,” engineers he wrote.
Source: Cloudflare
Secret loops used sophisticated leakage techniques. “This non -reported crawl machine used more IP that was not listed in the official IP range of Contplexity, and in response to restrictive robots and cloudflare block would turn through other evade web blocks.”
According to cloudflare, “declared” Spartlexity-TY search engines that are easily identifiable-the day they control 20-25 million applications, while unnounced secret-looking, which rely on shady tactics to hide their purpose-other 3-6 million requirements a day. “This activity has been observed over tens of thousands of domains and millions of requirements a day.”
Society did not respond UnscrambleRequest for comment. The spokesperson of the accusation rejected Techcrunch Like nothing but cloudflare “sales playground”.
Cloudflare CEO Matthew Prince was loud about what he sees as an unsustainable extraction of AI web content. “Searching recommendations for operation will fail because people are increasingly relying on AI summary.” In July, he revealed devastating conditions: while Google sends one visitor to every 18 pages that crawl, AI are much worse. The Openai ratio deteriorated from 250 to 1 six months ago to 1,500 per 1 today. Anthropic numbers are even more extreme and jump from 6,000 to 1 to 60 000 to 1 in the same period.
Source: Cloudflare
This has forced Cloudflare to start what it calls “Content Independence”, which is the default blocking AI for all new domains and become a de-facto vigilant that protects the creator from the threats of annoying AI search.
As Unscramble previously reportedMore than a million websites have decided to block since last autumn, with the main publishers including Associated Press, Time, Atlantic, BuzzfeedReddit, Quora and Universal Music Group join the movement.
“There are clear preferences that search engines should be transparent, serve a clear purpose, perform specific activities and most importantly, to follow directives and websites preferences,” Cloudflare said. The company contrasted the behavior of confusion with OpenI, which said it rightly respects the robots.
The reaction of cloudflare includes both immediate technical measures and long -term initiatives. The company deployed matches for signatures for secret browsing into its managed rules, which are available to all customers, including free users. It is also the development of tools such as “Labyrinth AI”, which captures unsatisfactory robots in false content, and the “Pay-Per-Crawl” market that would allow publishers to charge AI for access to their content.
Generally intelligent Bulletin
Weekly journey AI narrated gene, generative model AI.