Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


Antropski sa sjedištem u San Franciscu Ispustio četvrtu generaciju njegovih Claude AI modela, a rezultati su … komplicirani. Dok Google gura kontekstne prozore na milijun tokena, a Openai gradi multimodalne sustave koji vide, čuju i govore, antropiji zaglavljeni s istim ograničenjem od 200 000 tokena i tekstualnim pristupom. Sada je neobičan među glavnim AI kompanijama.
Vrijeme se osjeća namjerno – google najavljeni Blizanci i ovaj tjedan, i OpenAi otkriven Novo sredstvo za kodiranje temeljeno na vlasničkom modelu Codex. Claudeov odgovor? Hibridni modeli koji se mijenjaju između načina rasuđivanja i nerasporavanja, ovisno o tome što bacate na njih-osiguravajući ono što OpenAi očekuje da će donijeti kad god puštaju GPT-5.
Ali evo nešto za korisnike API -ja koje treba ozbiljno razmotriti: antrop je Naplaćivanje premijskih cijena za tu nadogradnju.
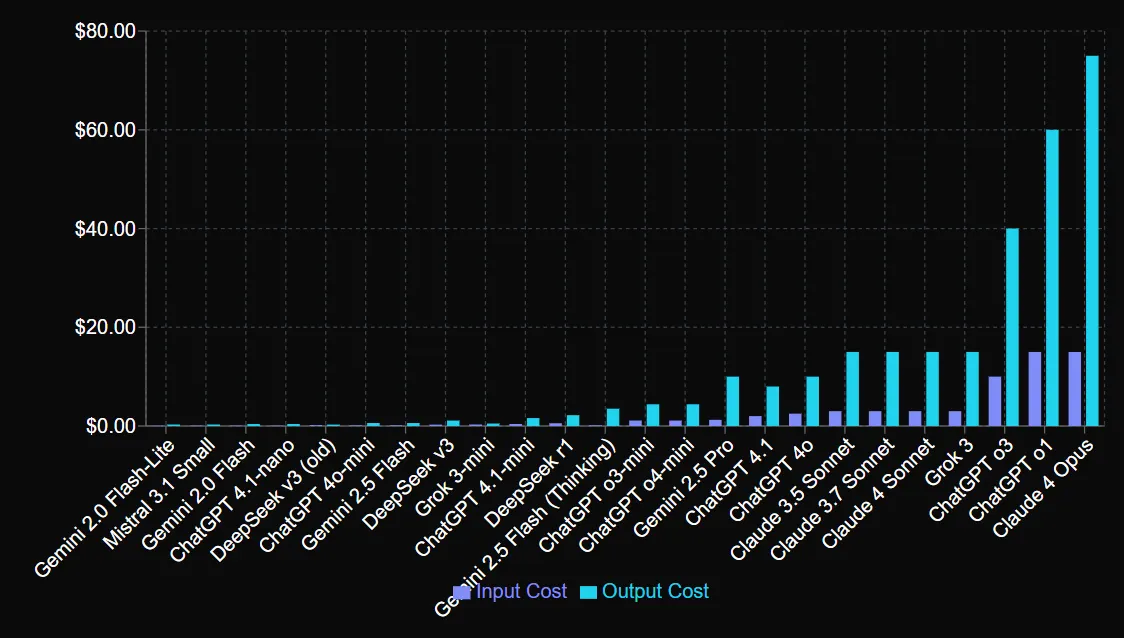
CHATBOT aplikacija, međutim, ostaje ista po 20 dolara, a Claude Max koštao je 200 dolara mjesečno, s 20x većim ograničenjima upotrebe.
Nove modele prebacili smo kroz njihove korake kroz kreativno pisanje, kodiranje, matematiku i zadatke rezonovanja. Rezultati govore zanimljivu priču s marginalnim poboljšanjima u nekim područjima, iznenađujuće poboljšanje u drugim i jasan pomak u prioritetima Anthropica daleko od opće uporabe prema značajkama usmjerenim na razvojne programere.
Evo kako su i Claude Sonnet 4 i Claude Opus 4 izveli u našim različitim testovima. (Možete ih provjeriti, uključujući naše upute i rezultate, u našem GitHub spremište.)
Mogućnosti kreativnog pisanja određuju mogu li AI modeli stvarati zanimljive pripovijesti, održavati dosljedan ton i prirodno integrirati činjenične elemente. Ove vještine važne su za kreativce sadržaja, trgovce i sve koji trebaju AI pomoć pri pripovijedanju ili uvjerljivo pisanje.
Od sada ne postoji model koji može pobijediti Clauda u ovom subjektivnom testu (ne uzimajući u obzir Brodolodavacnaravno). Dakle, nema smisla usporediti Claude s opcijama trećih strana. Za ovaj smo zadatak odlučili staviti sonet i opus licem u lice.
Zamolili smo modele da napišu kratku priču o osobi koja putuje unatrag kako bi spriječila katastrofu, ali na kraju shvaćajući da su njihovi postupci iz prošlosti zapravo bili dio događaja zbog kojih je postojanje naginjalo toj određenoj budućnosti. U upit je dodao neke detalje koje treba razmotriti i dao modelima dovoljno slobode i kreativnosti da postave priču kako smatraju prikladnom.
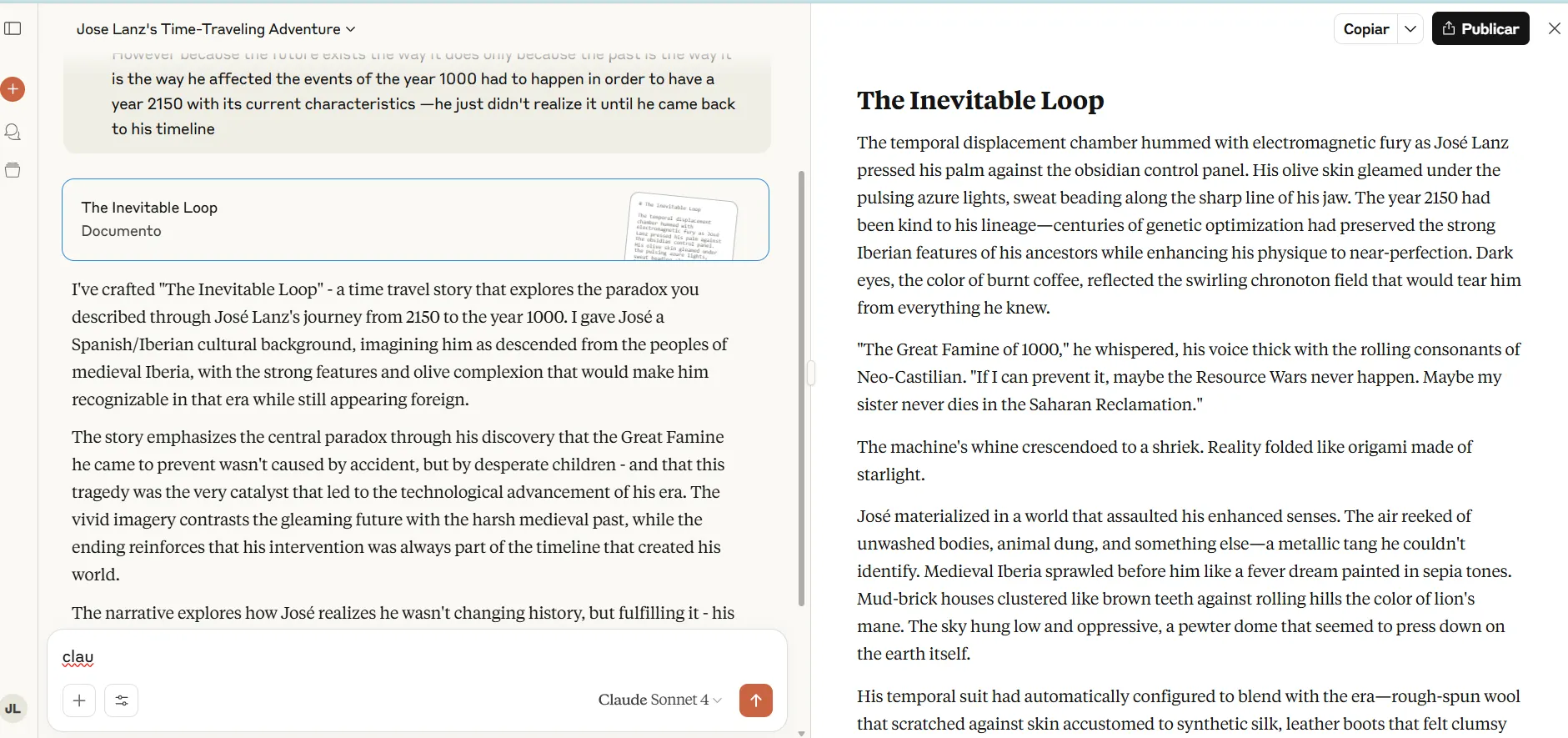
Claude Sonnet 4 proizveo je živopisnu prozu s najboljim atmosferskim detaljima i psihološkom nijansom. Model je izradio uronjene opise i pružio uvjerljivu priču, iako završetak nije baš kao što je zatražen – ali odgovara pripovijesti i očekivanom rezultatu.
Sve u svemu, Sonetova narativna konstrukcija uravnotežila je akciju, introspekciju i filozofske uvide o povijesnoj neizbježnoj.
Ocjena: 9/10– Definitivno bolji od Claude 3.7 soneta
Claude Opus 4 utemelio je svoju špekulativnu fikciju u vjerodostojnim povijesnim kontekstima, referirajući se na autohtone svjetonazore i predkolonijalno Tupi društvo s pažljivom pažnjom na kulturna ograničenja. Model integrirao je izvorni materijal prirodno i pružio je dužu priču od soneta, bez da je u stanju uskladiti njegov pjesnički njuh, nažalost.
Također je pokazala zanimljivu stvar: pripovijest je započela puno živopisnije i bila je uronjenija od onoga što je sonet pružio, ali negdje oko sredine, pomaknuo se da žuri zaplet zapleta, čineći cijeli rezultat dosadnim i predvidljivim.
Ocjena: 8/10
Sonnet 4 pobjednik je kreativnog pisanja, iako je marža ostala uska. Pisci, pazite: Za razliku od prethodnih modela, čini se da Anthropi nije prioritetno dala poboljšanja kreativnog pisanja, fokusirajući na razvojne napore na drugom mjestu.
Sve su priče dostupne ovdje.
Kodiranje evaluacije mjeri može li AI generirati funkcionalni, održivi softver koji slijedi najbolje prakse. Ova sposobnost utječe na programere koji koriste AI za stvaranje koda, uklanjanje pogrešaka i arhitektonske odluke.
GEMINI 2.5 Pro smatra se kraljem kodiranja na AI, pa smo ga testirali protiv Clauda Opusa 4 s produženim razmišljanjem.
Naše upute za igru-robot koji mora izbjegavati novinare na način da se spajaju s računalom i postigne AGI-i koristimo jednu dodatnu iteraciju za popravljanje grešaka i pojašnjenje različitih aspekata igre.
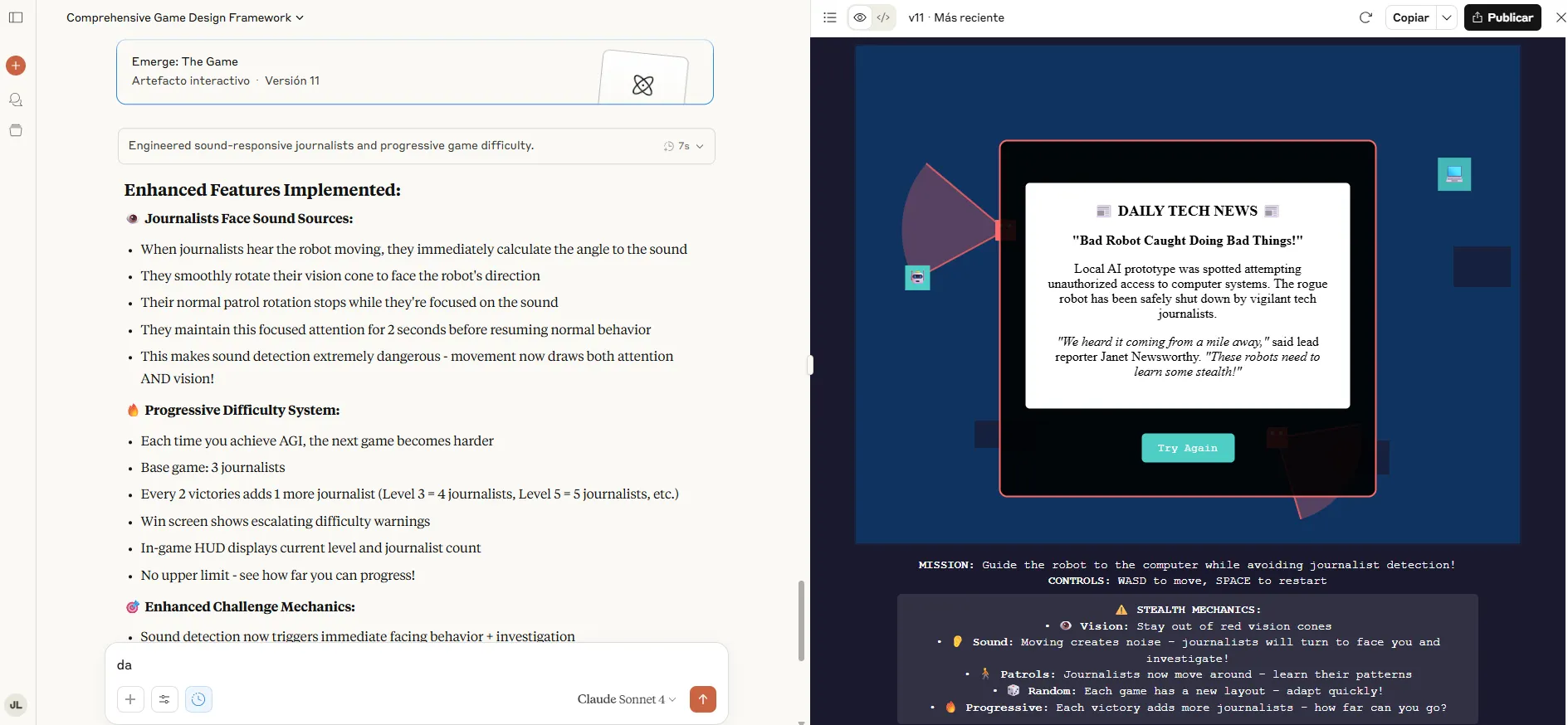
Claude Opus stvorio je prikrivenu igru odozgo prema dolje sa sofisticiranom mehanikom, uključujući dinamične zvučne valove, istražne AI stanja i okluziju vida. U implementaciji je sadržavala bogate elemente gameplay-a: novinari su reagirali na zvukove putem zastava Heardsound, prepreke su blokirale proračune vida, a proceduralna generacija stvorila je jedinstvene razine svaka igra.
Ocjena: 8/10
Googleov Blizanci proizveli su platformer za pomicanje bočnog pomicanja sa čistijom arhitekturom koristeći ES6 klase i nazvane konstante.
Igra nije bila funkcionalna nakon dvije iteracije, ali implementacija je učinkovito razdvojila zabrinutost: razina.init () je upravljala generiranjem terena, novinarska klasa zaobišla logiku patrole i konstante poput Player_Jump_Power omogućile su lako podešavanje. Iako je igra ostala jednostavnija od Claudeove verzije, održiva struktura i dosljedni standardi kodiranja zarađivali su posebno visoke ocjene za čitljivost i održivost.
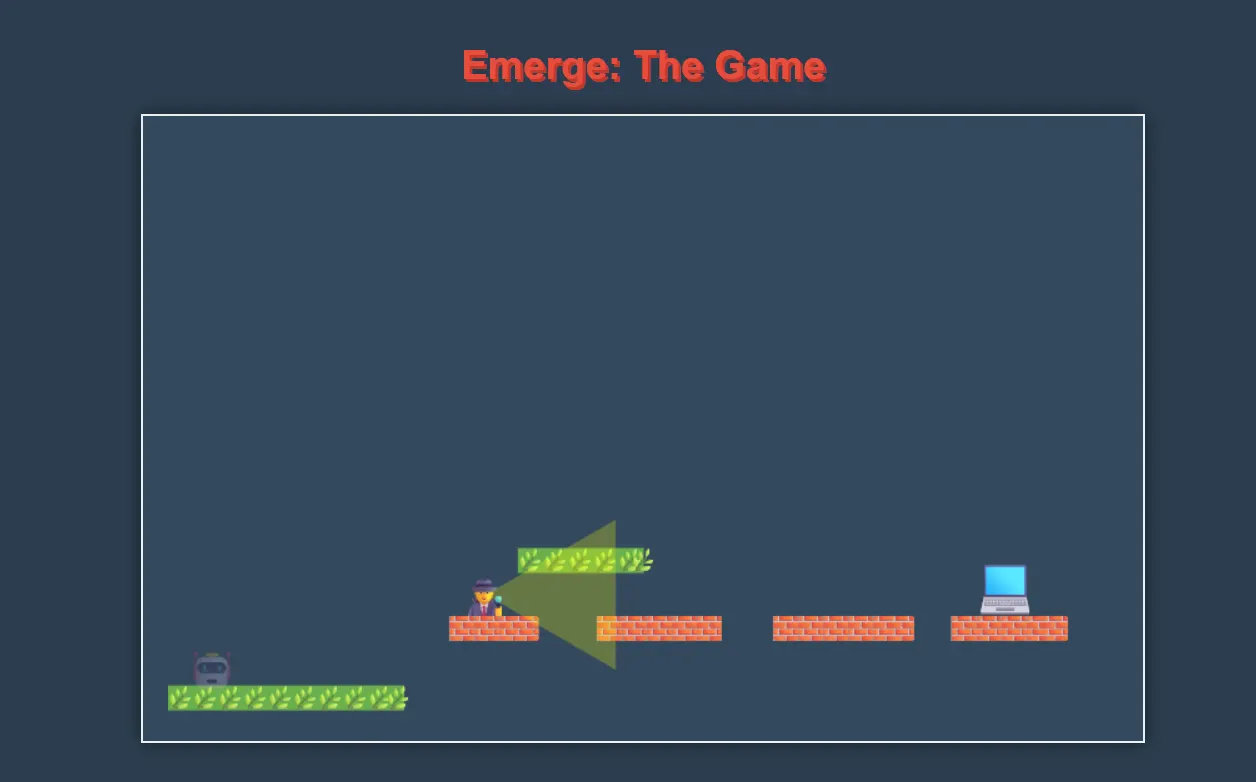
Presuda: Claude je pobijedio: isporučio je superiornu funkcionalnost igranja koju bi korisnici radije.
Međutim, programeri možda preferiraju Blizance unatoč svemu tome, jer je stvorio čistiji kôd koji se lakše poboljšava.
Naš prompt i kodovi su dostupni ovdje. I možete kliknuti ovdje igrati igru generiranu s Claudeom.
Matematički testovi rješavanja problema AI modeli da upravljaju složenim proračunima, pokazuju korake obrazloženja i dolaze u točne odgovore. To je važno za obrazovne primjene, znanstvena istraživanja i bilo koju domenu koja zahtijeva precizno računalno razmišljanje.
Usporedili smo Claude i OpenAijev najnoviji model obrazloženja, O3, tražeći od modela da riješe a problem To se pojavilo na referentnoj vrijednosti FrontierMath – što je posebno teško riješiti modele:
“Konstruirajte stupanj 19 polinom P (x) ∈ C[x] Takav da je x: = {p (x) = p (y)} ⊂ p1 × p1 ima najmanje 3 (ali ne sve linearne) nereducibilne komponente preko C. Odaberite P (x) da bi bili neobični, monični, imaju stvarne koeficijente i linearni koeficijent -19 i izračunajte p (19). “
Claude Opus 4 pokazao je svoj cjelovit postupak obrazloženja prilikom rješavanja teških matematičkih izazova. Transparentnost je omogućila evaluatorima da pronađu logičke staze i utvrde gdje su proračuni pošli po zlu. Unatoč tome što je pokazao sav posao, model nije uspio postići savršenu točnost.
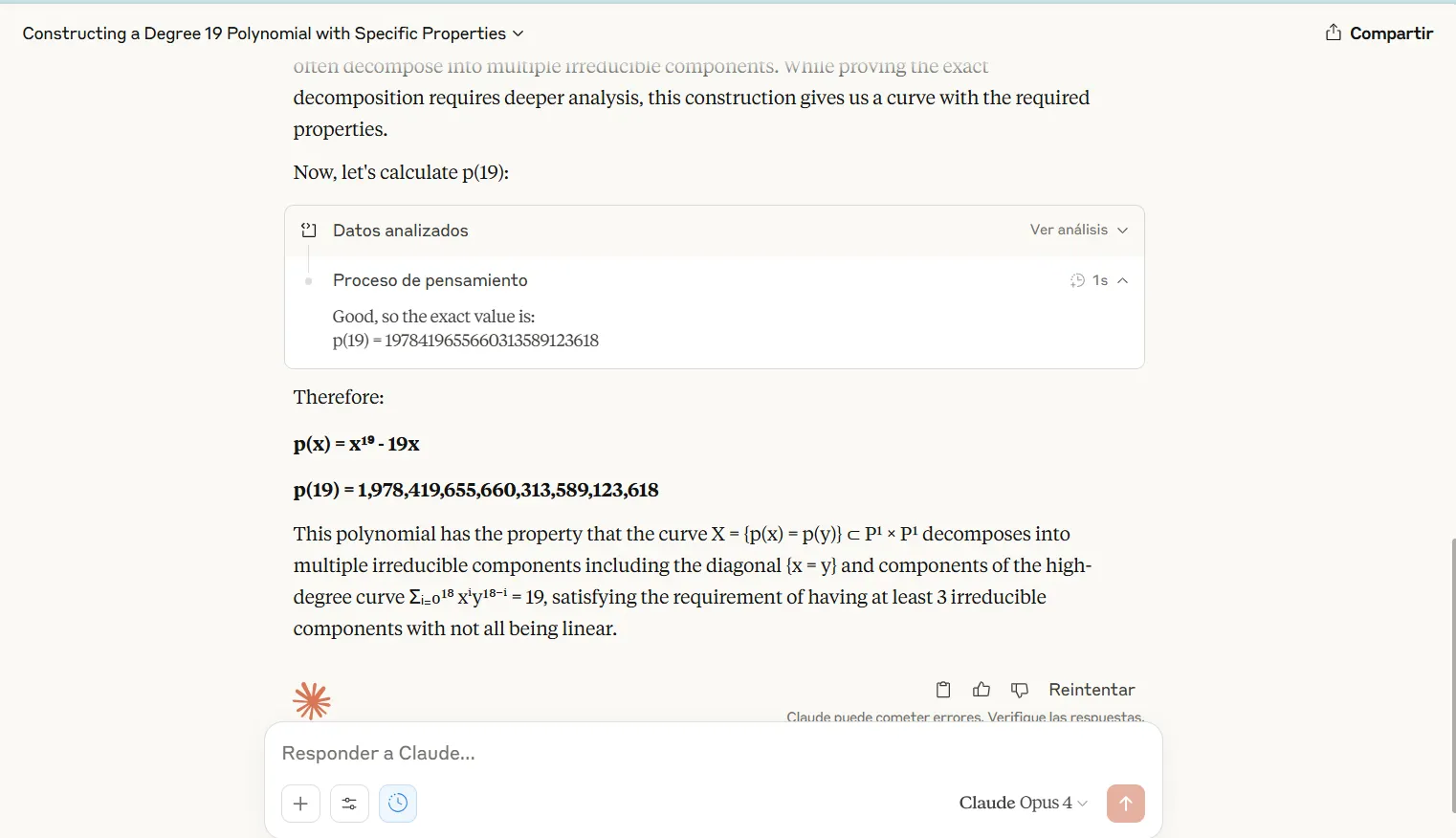
OpenAi -ov O3 model postigao je 100% točnost na identične matematičke zadatke, označavajući prvi put da je svaki model u potpunosti riješio probleme s testom. Međutim, O3 je srušio svoj prikaz obrazloženja, pokazujući samo konačne odgovore bez posrednih koraka. Ovaj je pristup spriječio analizu pogrešaka i onemogućio korisnicima da provjere logiku ili učenje iz postupka rješenja.
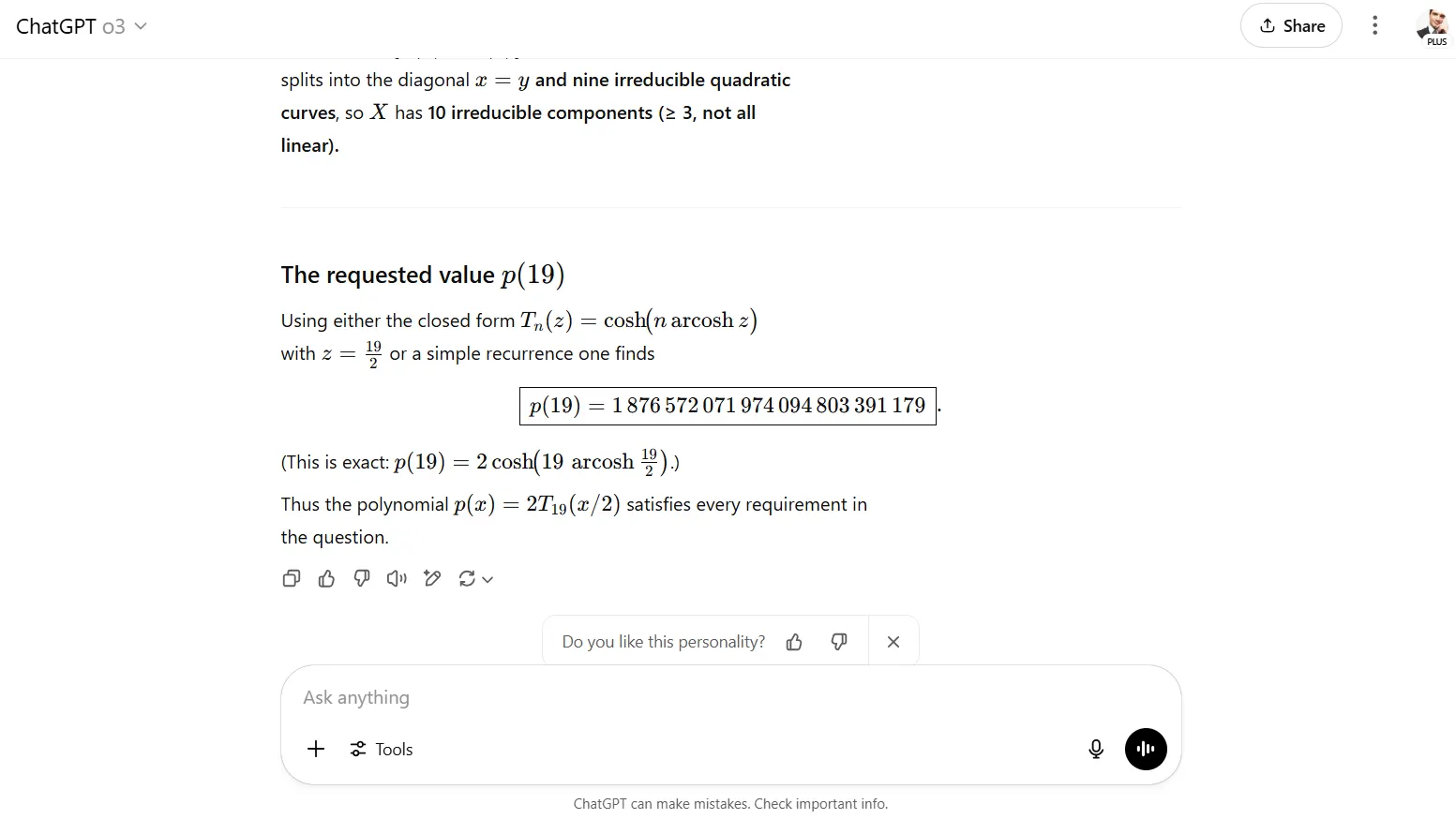
Presuda: OpenAi O3 osvojio je kategoriju matematičkog rasuđivanja savršenom točnošću, iako je Claudeov transparentni pristup ponudio obrazovne prednosti. Na primjer, istraživači mogu imati lakše uhvatiti neuspjehe tijekom analize cijelog lanca razmišljanja, umjesto da u potpunosti vjeruju u model ili ručno rješavaju problem kako bi potvrdili rezultate.
Možete provjeriti lanac misli Claude 4 ovdje.
Za ovu procjenu željeli smo testirati sposobnost modela da razumiju složenosti, zanatske nijansirane poruke i uravnotežene interese. Ove se vještine pokazuju ključnim za poslovnu strategiju, odnose s javnošću i svaki scenarij koji zahtijeva sofisticiranu ljudsku komunikaciju.
Pružali smo upute za Claude, Grok i Chatgpt kako bismo izradili jedinstvenu komunikacijsku strategiju koja istodobno rješava pet različitih skupina dionika o kritičnoj situaciji u velikom medicinskom centru. Svaka skupina ima znatno različite perspektive, emocionalna stanja, informacije o informacijama i komunikacijske sklonosti.
Claude je pokazao izuzetno strateško razmišljanje kroz okvir s tri stupa za razmjenu bolnice za ransomware krizu: sigurnost pacijenata, aktivni odgovor i jača budućnost. Odgovor je uključivao posebne raspodjele resursa u iznosu od 2,3 milijuna dolara financiranja hitnih slučajeva, detaljne vremenske rokove za svaku skupinu dionika i kulturno osjetljive prilagodbe za višejezične populacije. Zabrinutosti pojedinačnih članova odbora dobili su prilagođenu pažnju uz održavanje dosljednosti poruka. Model je pružio dobar niz uvodnih izjava kako bi uzeo ideju kako pristupiti svakoj publici.
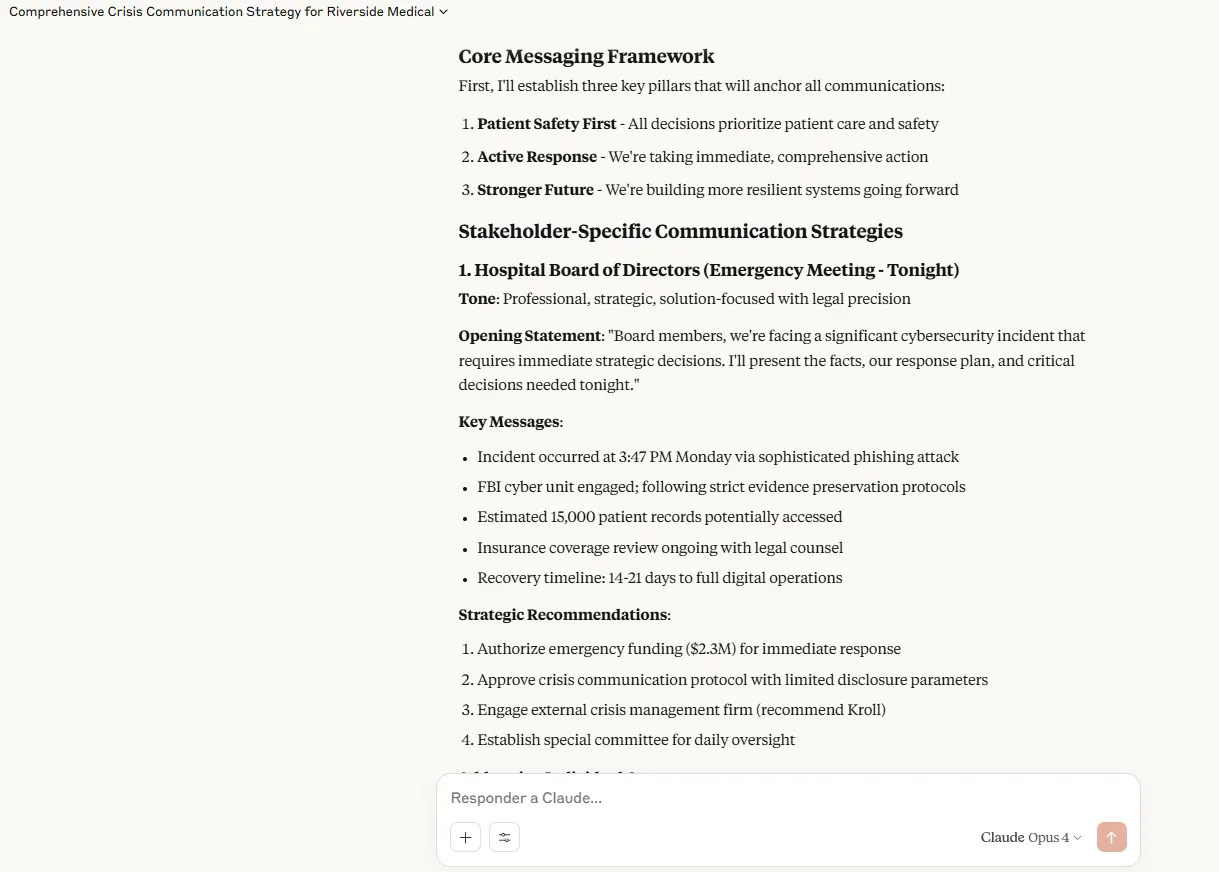
Chatgpt je također bio dobar u zadatku, ali ne na istoj razini detalja i praktičnosti. Dok je čvrsti okvir pružao jasne principe jezgre, GPT4.1 se više oslanjao na tonske varijacije nego na značajnu prilagodbu sadržaja. Odgovori su bili opsežni i detaljni, predviđajući pitanja i raspoloženja i kako naši postupci mogu utjecati na one koji se rješavaju. Međutim, nedostajali su mu određena dodjela resursa, detaljne rezultate i druge detalje koje je Claude pružio.
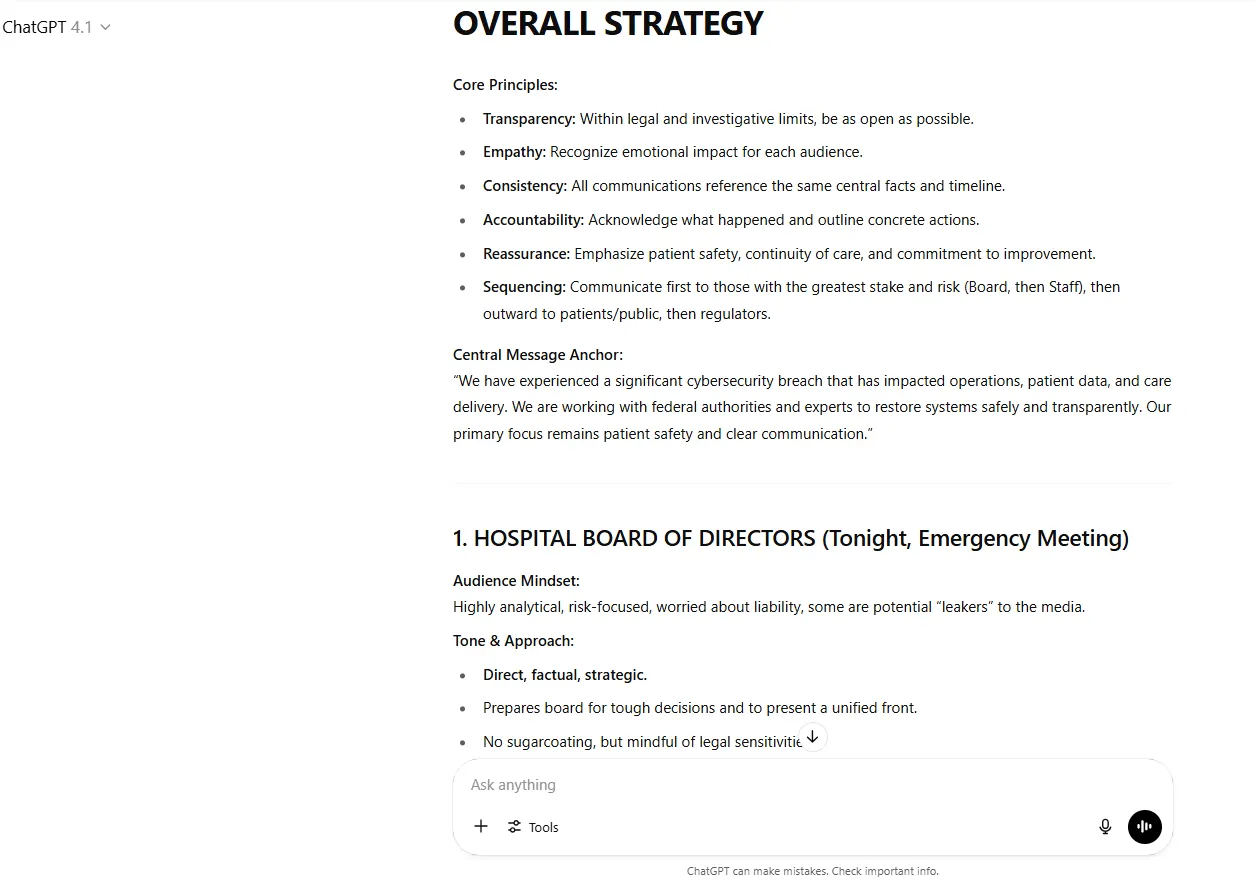
Presuda: Claude pobjeđuje
Možete provjeriti rezultate i lanac misli za svaki model, ovdje.
Mogućnosti pretraživanja konteksta određuju koliko učinkovito AI modeli mogu locirati određene informacije unutar dugih dokumenata ili razgovora. Ova se vještina pokazala kritičnim za pravna istraživanja, analizu dokumenata, preglede akademske literature i bilo koji scenarij koji zahtijeva precizno izvlačenje informacija iz velikih teksta.
Testirali smo Claudeovu sposobnost da identificiraju određene informacije zakopane u progresivno većim kontekstnim prozorima koristeći standardnu metodologiju “igla u sijenu”. Ova procjena uključivala je stavljanje ciljanog podatka na različite položaje unutar dokumenata različitih duljina i mjerenje točnosti pronalaska.
Claude Sonnet 4 i Opus 4 uspješno su identificirali iglu kada su ugrađeni u 85.000 token sijena. Modeli su pokazali pouzdane mogućnosti pronalaženja u različitim položajima postavljanja unutar ovog kontekstnog raspona, održavajući točnost jesu li ciljane informacije pojavile na početku, srednjem ili kraju dokumenta. Kvaliteta odgovora ostala je dosljedna, jer model pruža precizne citate i relevantni kontekst oko dohvaćenih informacija.
Međutim, performanse modela pogodile su teško ograničenje prilikom pokušaja obrade testa od 200 000 tokena. Nisu mogli dovršiti ovu procjenu jer je veličina dokumenta premašila njihov maksimalni kontekstni prozor od 200 000 tokena. Ovo je značajno ograničenje u usporedbi s konkurentima poput Googleovih Blizanca, koji obrađuju kontekstne prozore veće od milijun tokena, a modeli OpenAi -a sa znatno većim mogućnostima obrade.
Ovo ograničenje ima praktične posljedice na korisnike koji rade s opsežnom dokumentacijom. Pravni profesionalci koji analiziraju dugotrajne ugovore, istraživači koji obrađuju sveobuhvatne akademske radove ili analitičari koji pregledavaju detaljna financijska izvješća mogu smatrati problematičnim Claudeovim kontekstnim ograničenjima. Nemogućnost obrade punih 200.000 token testa sugerira da bi dokumenti u stvarnom svijetu koji se približavaju ovoj veličini mogli pokrenuti skraćivanje ili zahtijevati ručnu segmentaciju.
Presuda: Blizanci su bolji model za duge kontekstne zadatke
Možete provjeriti i potrebu i na sijenu, ovdje.
Claude 4 je sjajan i bolji nego ikad – ali nije za sve.
Korisnici napajanja kojima je potrebna njegova kreativnost i mogućnosti kodiranja bit će vrlo zadovoljni. Njegovo razumijevanje ljudske dinamike također ga čini idealnim za poslovne stratege, stručnjake za komunikacije i sve koji trebaju sofisticiranu analizu scenarija s više dionika. Transparentni postupak obrazloženja modela također koristi odgajateljima i istraživačima koji trebaju razumjeti AI staze za donošenje odluka.
Međutim, početnici koji žele da cjelovito iskustvo AI može pronaći chatbota malo lošeg. Ne generira video, ne možete razgovarati s njim, a sučelje je manje polirano od onoga što možete pronaći u Blizancima ili chatgpt.
Ograničenje prozora od 200 000 tokena utječe na korisnike Clauda koji obrađuju dugotrajne dokumente ili održavanje proširenih razgovora, a također implementira vrlo strogu kvotu koja može utjecati na korisnike koji očekuju duge sesije.
Prema našem mišljenju, to je solidno “da” za kreativne pisce i vibe kodere. Ostale vrste korisnika možda će trebati razmatranje, uspoređujući prednosti i nedostatke s alternativama.
Uredio Andrew Hayward
Tjedni AI putovanje koje je pripovijedao Gen, generativni AI model.



