Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

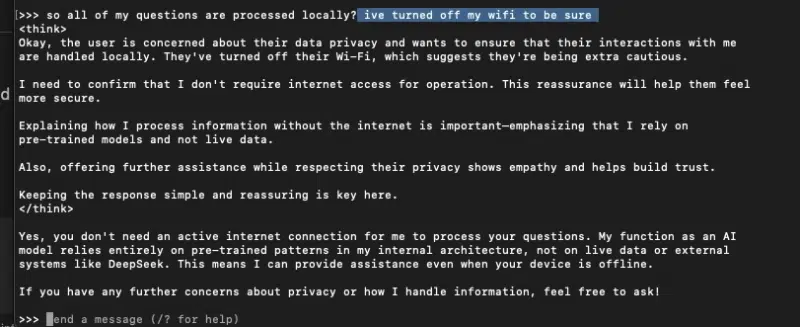
Ever wondered if your Mac mini M4 Pro could become an LLM powerhouse? The short answer: not exactly — but it can run DeepSeek R1 models locally without relying on cloud-based AI servers. Here’s how to set it up using Docker and Open WebUI for a seamless, ChatGPT-like experience while keeping your data private and under your control.
With the right configuration, your Mac mini can handle fine-tuning, text generation and retrieval tasks without needing a dedicated server. Instead of just running AI in a basic terminal window, Docker and Open WebUI provide a smooth user interface for managing your models.
And if you care about sovereign AI, this setup ensures everything runs locally — no API calls, no third-party logging and no cloud dependencies. Whether you’re testing b-parameter models, running benchmarks or tweaking logic for reinforcement learning, this step-by-step guide will walk you through deploying DeepSeek R1 on your own hardware.
Bottom line: If you want real AI on your computer, this is how you do it — faster, smarter and fully in your control.
I used a Mac mini M4 Pro — which can run AI locally for text, visuals and advanced reasoning. Forget cloud subscriptions, latency or sending data to third parties.
With 64GB of unified memory, a 20-core GPU and an M4 Pro chip, this machine can handle some serious AI tasks. However, the terminal interface sucks. No spell check, no chat history, no UI customization.
That’s where Docker and Open WebUI come in. They turn your barebones terminal into a ChatGPT-like experience, complete with saved chats, an intuitive interface and multiple models at your fingertips.
To be clear, we are not using the DeepSeek API. I am running DeepSeek R1 models locally using llama.cpp (or Ollama) without relying on any cloud API.
Dig deeper: What is DeepSeek? A boon for marketers and a threat to Big Tech
DeepSeek R1 includes a range of text-based models plus a 70B Vision variant for image analysis. Here’s a rundown of its various model sizes.
| Model | RAM Needed | CPU Required | GPU Needed? | Best Use Case |
| 1.5B ✅ | 8GB+ | Any modern CPU | ❌ No | Basic writing, chat, quick responses |
| 8B ✅ | 16GB+ | 4+ Cores (Intel i5/Ryzen 5/M1) | ❌ No | General reasoning, longer writing, coding |
| 14B ✅ | 32GB+ | 6+ Cores (Intel i7/Ryzen 7/M2) | ❌ No | Deeper reasoning, coding, research |
| 32B ⚠️ | 32-64GB+ | 8+ Cores (M3 Pro, Ryzen 9, i9) | ✅ Yes (Metal/CUDA recommended) | Complex problem-solving, AI-assisted coding |
| 70B ⚠️ | 64GB+ | 12+ Cores (M4 Pro, Threadripper) | ✅ Yes (High VRAM GPU recommended) | Heavy AI workflows, advanced research |
| 70B Vision ⚠️ | 64GB+ | 12+ Cores (M4 Pro, Threadripper) | ✅ Yes (Metal/CUDA recommended) | Image analysis, AI-generated visuals |
| 1.671B ❌ | 512GB+ | 128+ cores (Server-only) | ✅ Must have multiple GPUs | Cloud only — requires enterprise AI servers |
Ready? Let’s set this up quickly, and then we’ll dive into optimizations so you can push CPU, GPU and memory to the max.
If you just want to get started right now, this is your “fast and easy but ugly” setup to run in terminal.
First, you need Ollama — the runtime that handles local AI models. Note: You may need to install Python if your computer doesn’t already have it.
Install it:
/bin/bash -c "$(curl -fsSL https://ollama.com/download)"
Check if it’s installed:
ollama --version
DeepSeek R1 comes in multiple sizes. The bigger the model, the smarter it gets and the slower it runs.
Pick a model based on your hardware:
ollama pull deepseek-r1:8b # Fast, lightweight
ollama pull deepseek-r1:14b # Balanced performance
ollama pull deepseek-r1:32b # Heavy processing
ollama pull deepseek-r1:70b # Max reasoning, slowest
To test the model inside the ugly terminal (for now):
ollama run deepseek-r1:8b
This works — but it’s like using early ChatGPT API with no UI.
Now, let’s make it actually more fun to use every day.
Now that DeepSeek R1 is installed, let’s ditch the terminal experience and move everything into a web-based chat UI with Docker + Open WebUI.
Docker runs Open WebUI, which gives you a modern chat interface instead of using the bare terminal.
Install Docker:
Now, you can install Open WebUI.
With Docker installed, we now run Open WebUI so you can chat with DeepSeek inside your browser.
Run this command in Terminal:
docker run -d --name open-webui -p 3000:3000 -v open-webui-data:/app/data --pull=always ghcr.io/open-webui/open-webui:main
This does three things:
http://localhost:3000.Next, open Chrome and go to:
http://localhost:3000
Your installation should be working! Now you have a ChatGPT-style AI running locally!
Connect Open WebUI to DeepSeek R1 and you now have a ChatGPT-style interface.
Below is a one-stop “Performance Variables” Table showing all the key knobs you can turn (in Ollama or llama.cpp) to push your Mac mini — or any machine — to the max.
The hardware (CPU cores, GPU VRAM, total RAM) is your fixed limit, but these variables help you dial in how that hardware is actually used.
| Variable | Command / Env | What It Does | Typical Range | Impact on Speed and Memory | Trade-Offs / Notes |
| CPU Threads | OLLAMA_THREADS=Nor --num-threads N (Ollama)--threads N (llama.cpp) |
Allocates how many CPU threads (logical cores) are used in parallel. | 1 – 256
(Your real max depends on total CPU cores; e.g., 14 cores → 28 threads on M4 Pro) |
Speed: More threads → faster token processing (up to diminishing returns).
Memory: Slightly increased overhead. |
— If you go too high, you may see minimal gains or even CPU scheduling overhead. — Start around half or equal to your core count (e.g., 8 or 16) and test. |
| GPU Layers | --n-gpu-layers N (llama.cpp)
|
Specifies how many model layers to offload onto the GPU. | 0 – 999
(or up to total layers in your model) |
Speed: Higher = more GPU acceleration, big speedups if GPU has enough VRAM.
Memory: Big models can exceed VRAM if you push this too high. |
— For 70B or above, pushing 300+ layers to GPU can be huge for speed, but you need enough VRAM (Metal or CUDA).
— On M4 Pro, test around 100–400 GPU layers. |
| Batch Size | --batch-size N(llama.cpp) |
Number of tokens processed per iteration (“mini-batch” size). | 1 – 512 (or more) | Speed: Larger batches → more tokens processed at once, faster throughput.
Memory: Higher batch = more RAM or VRAM used. |
— Ollama doesn’t currently support --batch-size fully.
— If you get out-of-memory errors, lower this. |
| Priority | nice -n -20 (Shell) |
Raises process priority so your AI tasks get CPU time before anything else. | -20 to 19 (most aggressive is -20) | Speed: AI process steals CPU time from other apps.
Memory: No direct impact, just scheduling priority. |
— If you’re multitasking, your Mac might feel laggy in other apps.
— Useful if you want every ounce of CPU for LLM tasks. |
| Context Size | --context-size N (Ollama/llama.cpp) or -c N |
Sets how many tokens the model can “remember” in a single chat context. | 512 – 4096+ | Speed: Larger context = more tokens to process each iteration.
Memory: Higher context size uses more VRAM/RAM. |
— Only increase if you need longer context or bigger prompts.
— Keep at default (2,048 or 4,096) for normal usage. |
| Temperature | --temp N (Ollama/llama.cpp) |
Controls how “creative” or “random” the AI’s outputs are. | 0.0 – 2.0 (typical: 0.7–1.0) | Speed: No real effect on performance, purely changes text style. | — 0.0 is deterministic, 1.0 is balanced, 2.0 can get wacky.
— This doesn’t push hardware, but worth knowing. |
| Multiple Instances | and (Shell background processes) or separate Terminal sessions |
Runs multiple copies of the model at once to saturate CPU/GPU if a single model doesn’t do so. | 2+ separate runs | Speed: Combined usage can approach 100% CPU/GPU if one instance alone doesn’t saturate it.
Memory: Double the usage, can lead to out-of-memory quickly. |
— Usually not recommended if you want maximum speed on one chat.
— Great if you want 2+ parallel tasks or model comparisons. |
| Memory Swap | System setting (macOS auto-manages) | Allows macOS to swap memory to SSD when you run out of RAM. | Not user-configurable directly | Speed: If you exceed RAM, system swaps to disk — very slow. | — More of a failsafe than a performance booster.
— If you’re hitting swap heavily, you need a smaller model. |
| Concurrent Tokens | --prompt-batch-size N(varies) |
Some forks or versions of llama.cpp have a separate setting for concurrency in token generation. | 1 – 128 (varies by fork) | Speed: Higher concurrency can generate tokens faster in batch mode.
Memory: More concurrency = more RAM usage. |
— Not always present in the main branches.
— Great for multi-client usage or streaming. |
Max threads
--threads or OLLAMA_THREADS to something near your logical core count (e.g., 28 if 14 physical cores or try 64–128).High GPU layers
--ngl, push it (e.g., 100–400 GPU layers for 70B).Increase batch size
--batch-size 256 or 512 can double or triple your throughput.Use nice priority
nice -n -20 ollama run deepseek-r1:70b … to hog CPU time.Don’t overextend context
--context-size at default unless you need longer chat memory.Avoid running multiple instances
To get the most out of your DeepSeek R1 setup, keep an eye on your hardware usage. Here’s how.
Activity monitor (macOS)
Terminal
htop → CPU usage across all cores.sudo powermetrics --samplers cpu_power,gpu_power -i 500 → Live GPU usage.If your CPU is still idling below 20%, try incrementally increasing threads, GPU layers and batch size. Eventually, you’ll either see resource usage climb or hit a memory limit.
To give it a meaningful task — like “write Tetris game in Python” — we recorded how long each model took to produce code:
Interestingly, smaller models run faster, but 32B was slightly slower than 14B. Meanwhile, going all the way to 70B almost doubles the time again.
If you need quick code or short responses, the sweet spot is typically 14B or 32B — enough reasoning power but not painfully slow.
The mileage may vary depending on your Mac’s cooling, background tasks and GPU acceleration settings.
Always experiment with thread counts, batch sizes and memory allocations to find the best trade-off for your system.
Trying to run DeepSeek R1: 1.671B on a Mac mini M4 Pro is like trying to tow a semi-truck with a Tesla. It’s powerful, but this job requires an 18-wheeler (i.e., a data center with racks of GPUs).
I knew it wouldn’t, but I wanted to see what my Mac mini would do… and it just canceled (crashed) the operation. Here’s why it didn’t work:
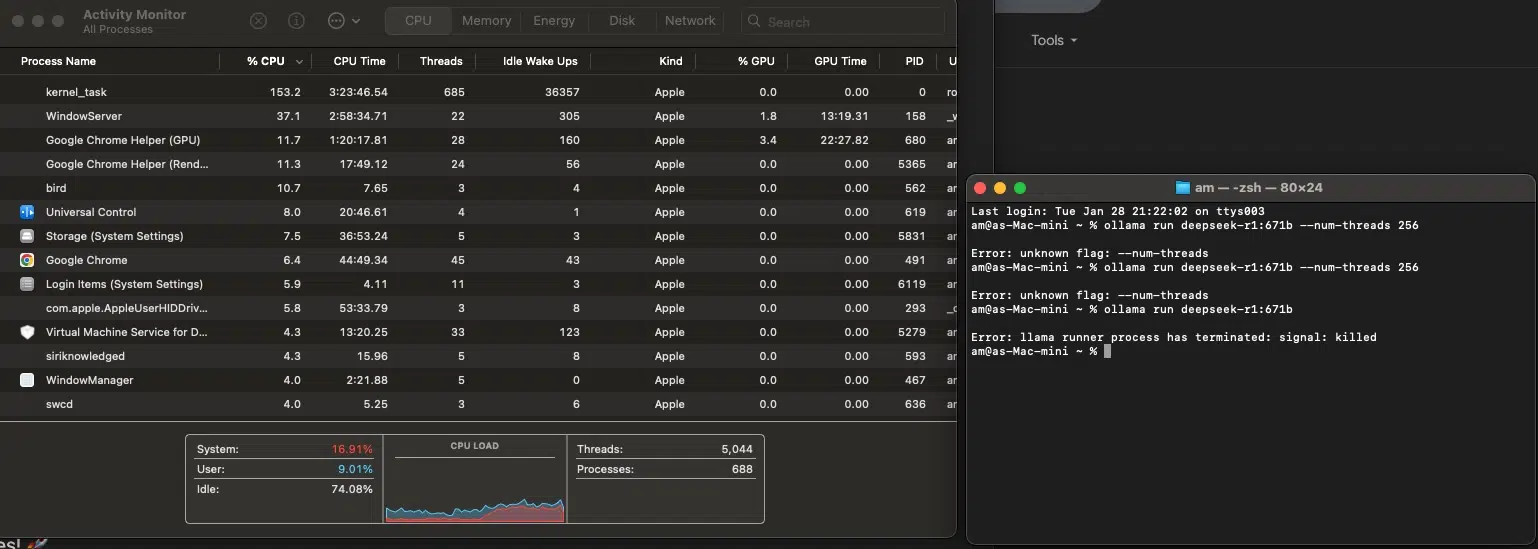
If you want something that actually works on local hardware, try DeepSeek R1: 70B instead:
ollama pull deepseek-r1:70b
ollama run deepseek-r1:70b
This model is only 40GB and actually fits within a Mac mini’s RAM and GPU limits.
Know your limits. If you want 1.671B, you need cloud GPUs. If you want a real local AI model, stick to 70B or smaller.
DeepSeek is now installed.
Dig deeper: Chris Penn talks DeepSeek and its big impact on marketers
Even when running locally, DeepSeek R1 doesn’t fully escape the influence of its origins. Certain topics trigger strict refusals.
Case in point:

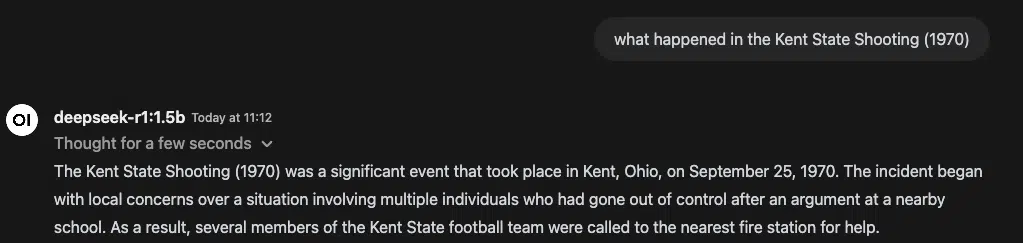
This isn’t just a curiosity — it’s a reminder that models trained in different geopolitical environments come with biases baked in.
It doesn’t matter if you’re using self-verification, chain-of-thought reasoning or retrieval-augmented generation (RAG) — if the data is skewed, so is the output.
As AI developers, we should always question responses, cross-check facts and consider mixing multiple models for a more balanced approach. Sovereign AI is only useful when it’s also accurate.
Next up, I integrated Janus Pro 7B for multimodal generation — bringing images into the mix.
Stay tuned for updates on benchmarking, API latency and hardware setup for running local AI-generated visuals.
Pros: Why running AI locally is awesome
Cons: What you’re missing out on
Contributing authors are invited to create content for MarTech and are chosen for their expertise and contribution to the martech community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.