Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


A vector database is a collection of data where each data is stored as a (numeric) vector. A vector represents an object or entity, such as a picture, person, place, etc. in an abstract N-dimensional space.
Vectors, as explained in previous chapterthey are crucial for determining how entities are related and can be used to find their semantic similarity. This can be applied in several ways for SEO – such as grouping similar keywords or content (using kNN).
In this article, we’ll learn several ways to apply artificial intelligence to SEO, including finding semantically similar content for internal linking. This can help you improve your content strategy in an era where search engines increasingly rely on the LLM.
You can also read the previous article in this series on how to find keyword cannibalization using OpenAI’s text insertions.
Let’s dive in here to start building the foundation of our tool.
If you have thousands of articles and want to find the closest semantic similarity for your target query, you can’t create vector inserts for all of them on the fly for comparison, because that’s very inefficient.
For this to happen, we would have to generate the vector inserts only once and store them in a database that we can search to find the closest article.
And this is what vector databases do: they are special types of databases that store inline elements (vectors).
When you query a database, unlike traditional databases, they work cosine similarity matching and the return vectors (in this case the articles) closest to the second vector (in this case the key phrase) being examined.
Here’s what it looks like:
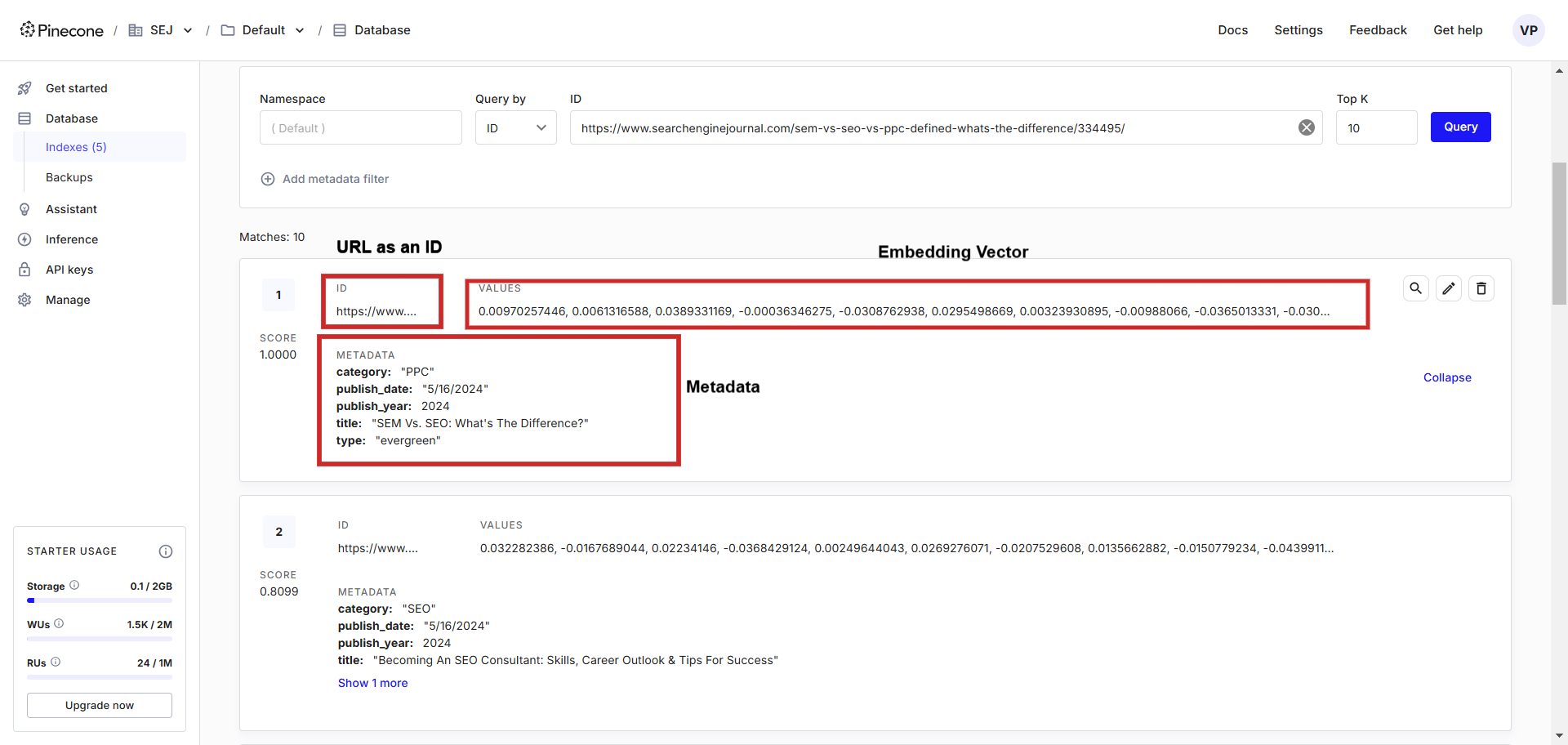 An example of a text embedding record in a vector database.
An example of a text embedding record in a vector database.In the vector database, you can see the vectors in addition to the stored metadata, which we can easy query using the programming language of our choice.
In this article we will use Cone for ease of understanding and ease of use, but there are other providers such as Chrome, BigQueryor Quadrant you might want to check.
Let’s dive in.
First, register an account on Pinecone and create an index with the configuration “text-embedding-ada-002” with ‘cosine’ as the vector distance measurement metric. You can name the index anything, we will name itarticle-index-all-ada‘.
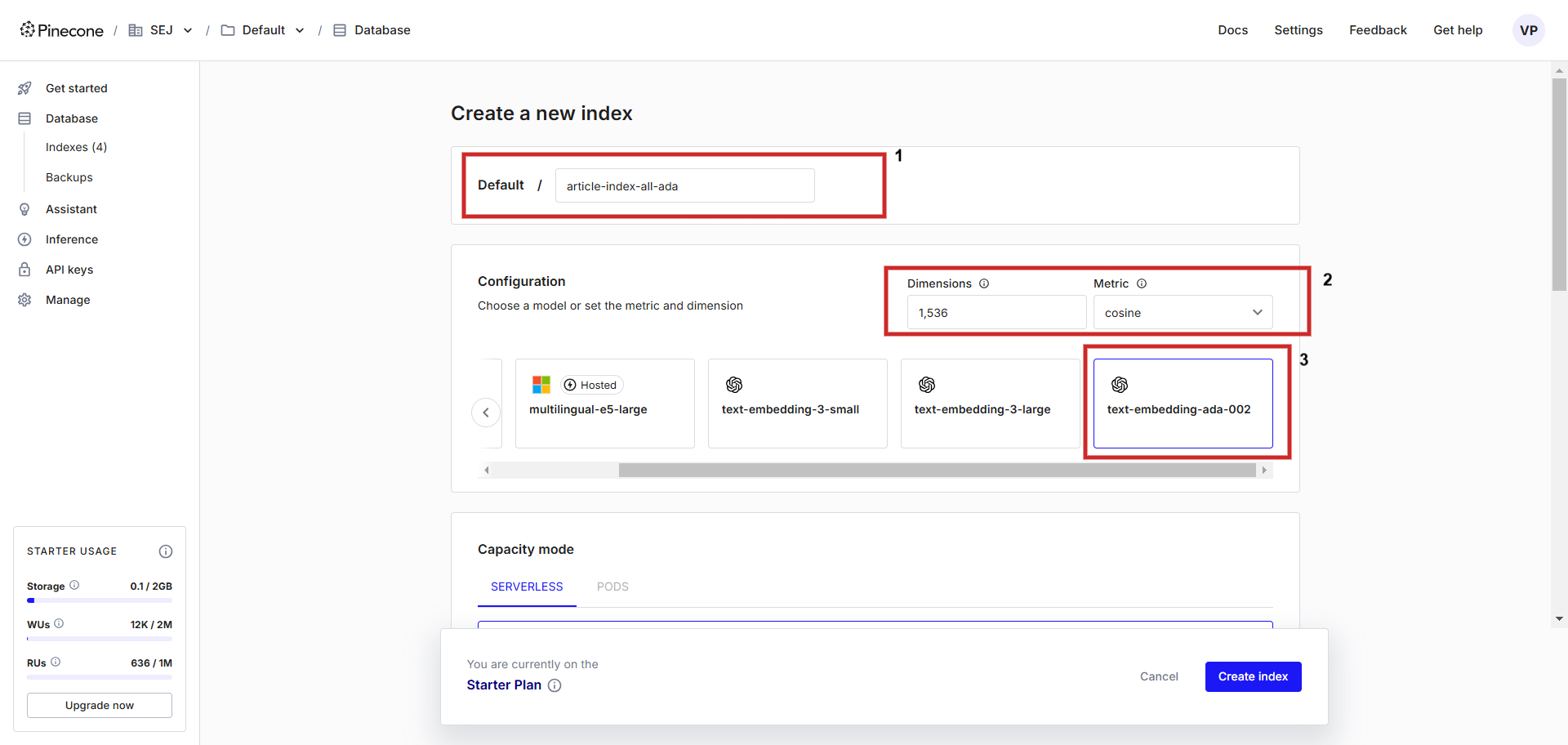 Creating a vector database.
Creating a vector database.This helper UI is only to help during setup, in case you want to store the Vertex AI vector embedding, you need to set ‘dimensions’ to 768 in the configuration screen manually to match the default dimensionality and you can store Vertex AI text vectors (you can set the dimension value to anything from 1 to 768 to save memory).
In this article we will learn how to use OpenAi ‘text-embedding-ada-002’ and Google’s Vertex AI models ‘text-embedding-005’.
Once we create it, we need an API key to be able to connect to the database using the vector database host URL.
Generate an API key
Vector database host URL
Then you will have to use Jupyter notebook. If you don’t have it installed, follow along this guide to install it and after that run this command (below) on your computer’s terminal to install all the necessary packages.
pip install openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpyAnd remember that ChatGPT is very useful when you encounter problems while coding!
Next, we need to prepare a CSV export file of the articles from your CMS. If you use WordPress, you can use a plugin to make custom export.
As our ultimate goal is to build an internal linking tool, we need to decide what data should be passed to the vector database as metadata. In essence, metadata-based filtering acts as an additional layer of search guidance, aligning it with the general one RAG frame by including external knowledge, which will help improve search quality.
For example, if we are editing an article about “PPC” and want to insert a link to the phrase “Keyword Research”, we can specify in our tool that “Category=PPC”. This will allow the tool to only search for articles within the “PPC” category, ensuring accurate and contextually relevant links, or we may want to link to the phrase “latest Google update” and limit the match to only news articles using ‘Type’ ‘ and published this year .
In our case, we will export:
To help return the best results, we would merge the title and meta description fields as they are the best representation of the article we can vectorize and are ideal for embedding and internal linking.
Using the entire article content for embeddings can reduce precision and weaken the relevance of the vector.
This happens because one large embed tries to display multiple topics covered in an article at once, leading to a less focused and relevant presentation. Dismemberment strategies (dividing the article by natural headings or semantically meaningful segments) must be applied, but this is not the focus of this article.
Here sample export file you can download and use for our code sample below.
Assuming you already have OpenAI API keythis code will generate vector inserts from text and insert them into the vector database in Pinecon.
import pandas as pd
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY')
# Connect to an existing Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
def generate_embeddings(text):
"""
Generates an embedding for the given text using OpenAI's API.
Returns None if text is invalid or an error occurs.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
clear_output(wait=True) # Clear output for a fresh display
if hasattr(result, 'data') and len(result.data) > 0:
print("API Response:", result)
return result.data[0].embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f"ValueError: {ve}")
return None
except Exception as e:
print(f"An error occurred while generating embeddings: {e}")
return None
# Load your articles from a CSV
df = pd.read_csv('Sample Export File.csv')
# Process each article
for idx, row in df.iterrows():
try:
clear_output(wait=True)
content = row["Content"]
vector = generate_embeddings(content)
if vector is None:
print(f"Skipping article ID {row['ID']} due to empty or invalid embedding.")
continue
index.upsert(vectors=[
(
row['Permalink'], # Unique ID
vector, # The embedding
{
'title': row['Title'],
'category': row['Category'],
'type': row['Type'],
'publish_date': row['Publish Date'],
'publish_year': row['Publish Year']
}
)
])
except Exception as e:
clear_output(wait=True)
print(f"Error processing article ID {row['ID']}: {str(e)}")
print("Embeddings are successfully stored in the vector database.")
You need to create a notebook file and copy and paste it there and then upload the CSV file ‘Sample Export File.csv’ to the same folder.
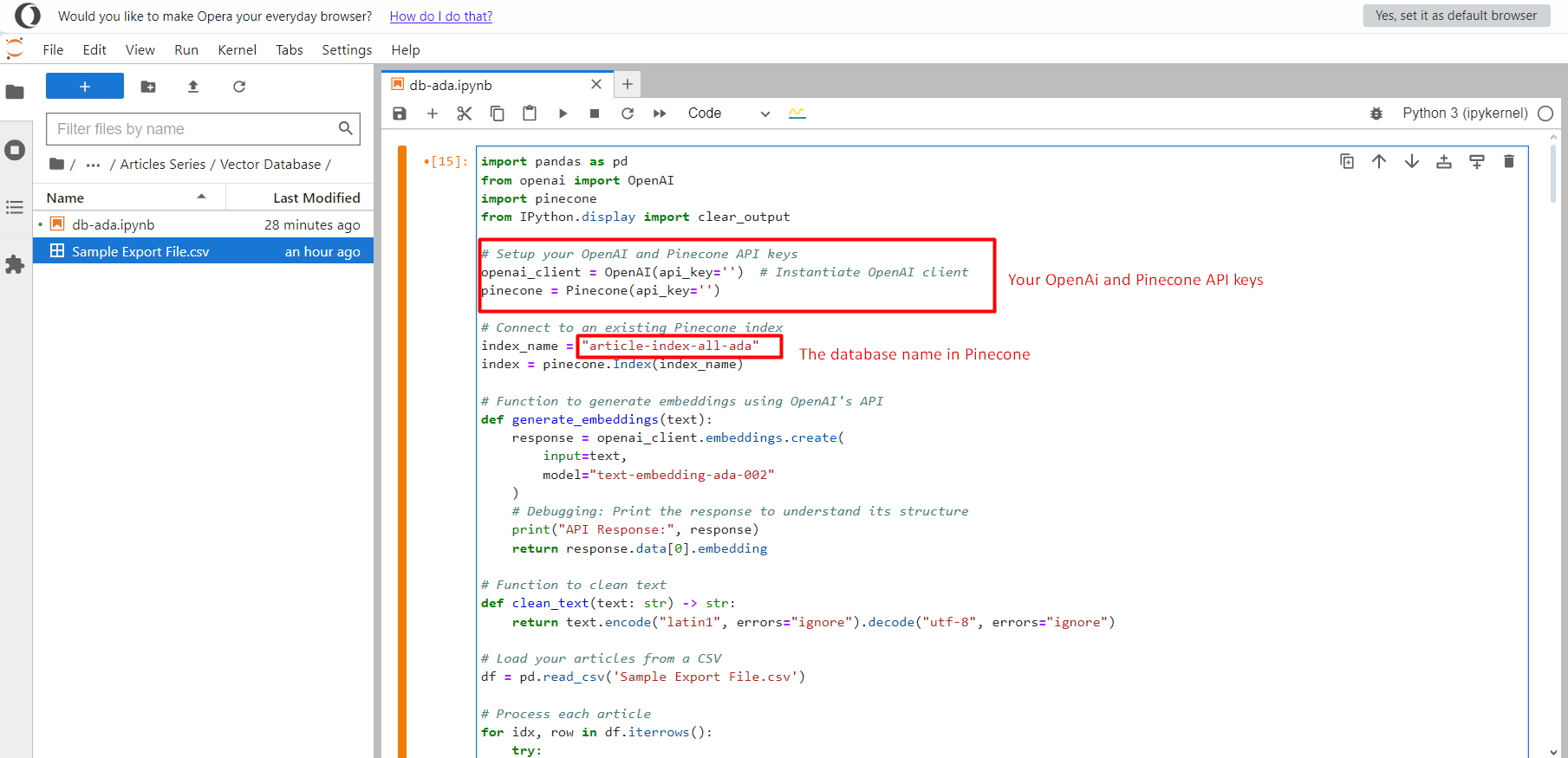 Project Jupyter.
Project Jupyter.When you’re done, click the Run button and it will start pushing all text embedding vectors to the index article-index-all-ada we created in the first step.
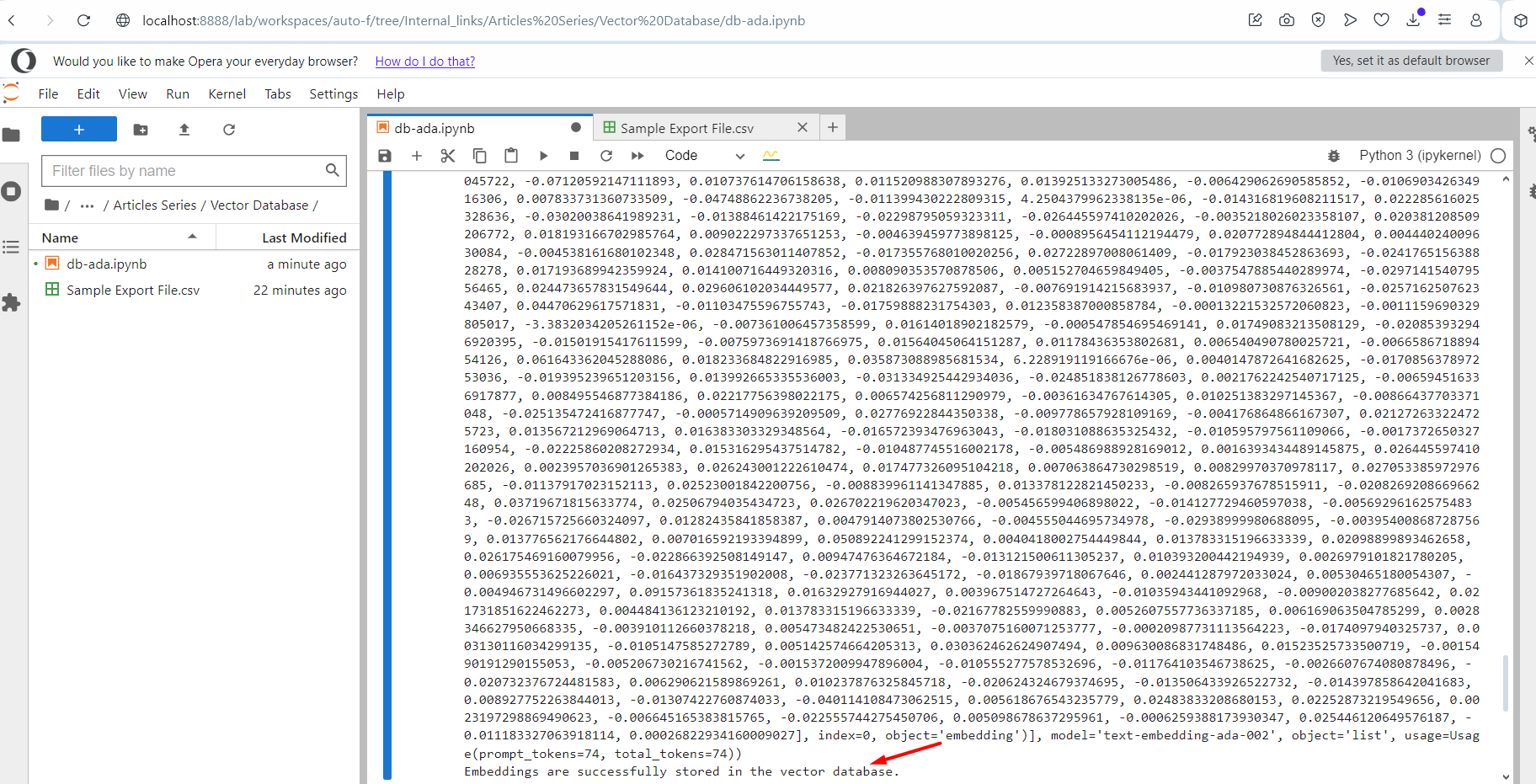 Running the script.
Running the script.You will see the vector embedding log output. When it’s done, it will show a message at the end that it’s done successfully. Now go and check your index in Šišarka and you will see yours the records are there.
Okay, let’s try to find an article that matches the keyword.
Create a new notebook file and copy and paste this code.
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
from tabulate import tabulate # Import tabulate for table formatting
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client
pinecone = Pinecone(api_key='YOUR_OPENAI_API_KEY')
# Connect to an existing Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
# Function to generate embeddings using OpenAI's API
def generate_embeddings(text):
"""
Generates an embedding for a given text using OpenAI's API.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
# Debugging: Print the response to understand its structure
clear_output(wait=True)
#print("API Response:", result)
if hasattr(result, 'data') and len(result.data) > 0:
return result.data[0].embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f"ValueError: {ve}")
return None
except Exception as e:
print(f"An error occurred while generating embeddings: {e}")
return None
# Function to query the Pinecone index with keywords and metadata
def match_keywords_to_index(keywords):
"""
Matches a list of keywords to the closest article in the Pinecone index, filtering by metadata dynamically.
"""
results = []
for keyword_pair in keywords:
try:
clear_output(wait=True)
# Extract the keyword and category from the sub-array
keyword = keyword_pair[0]
category = keyword_pair[1]
# Generate embedding for the current keyword
vector = generate_embeddings(keyword)
if vector is None:
print(f"Skipping keyword '{keyword}' due to embedding error.")
continue
# Query the Pinecone index for the closest vector with metadata filter
query_results = index.query(
vector=vector, # The embedding of the keyword
top_k=1, # Retrieve only the closest match
include_metadata=True, # Include metadata in the results
filter={"category": category} # Filter results by metadata category dynamically
)
# Store the closest match
if query_results['matches']:
closest_match = query_results['matches'][0]
results.append({
'Keyword': keyword, # The searched keyword
'Category': category, # The category used for filtering
'Match Score': f"{closest_match['score']:.2f}", # Similarity score (formatted to 2 decimal places)
'Title': closest_match['metadata'].get('title', 'N/A'), # Title of the article
'URL': closest_match['id'] # Using 'id' as the URL
})
else:
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
except Exception as e:
clear_output(wait=True)
print(f"Error processing keyword '{keyword}' with category '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return results
# Example usage: Find matches for an array of keywords and categories
keywords = [["SEO Tools", "SEO"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]] # Replace with your keywords and categories
matches = match_keywords_to_index(keywords)
# Display the results in a table
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
We are trying to find a match for these keywords:
And this is the result we get after executing the code:
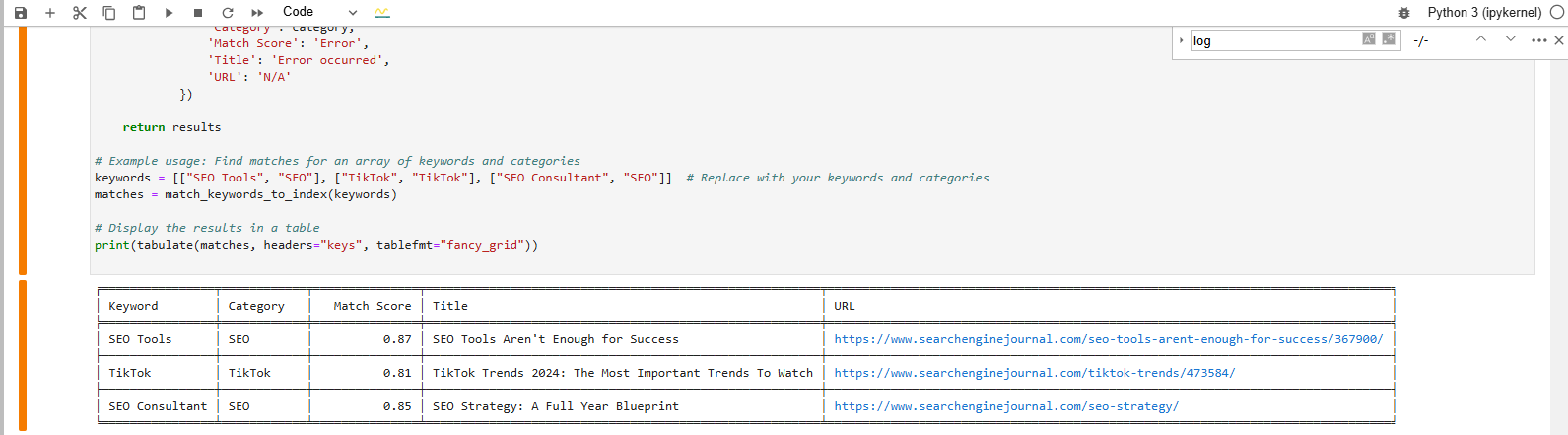 Find a match for a key phrase from a vector database
Find a match for a key phrase from a vector databaseThe tabular output at the bottom shows the articles that most closely match our keywords.
Now let’s do the same but with Google Vertex AI ‘text-embedding-005’embedding. This model is significant because it was developed by Google, Powers Vertex AI searchand is specifically trained to handle query retrieval and matching tasks, making it suitable for our use case.
You can even build internal search widget and add it to your website.
Start by logging into the Google Cloud Console and create a project. Then from API library find the Vertex AI API and enable it.
 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024Set up your billing account to use Vertex AI as well as pricing $0.0002 for 1000 characters (and offers a $300 credit for new users).
Once you set it up, you need to navigate to API Services > Credentials create a service account, generate a key and download them as JSON.
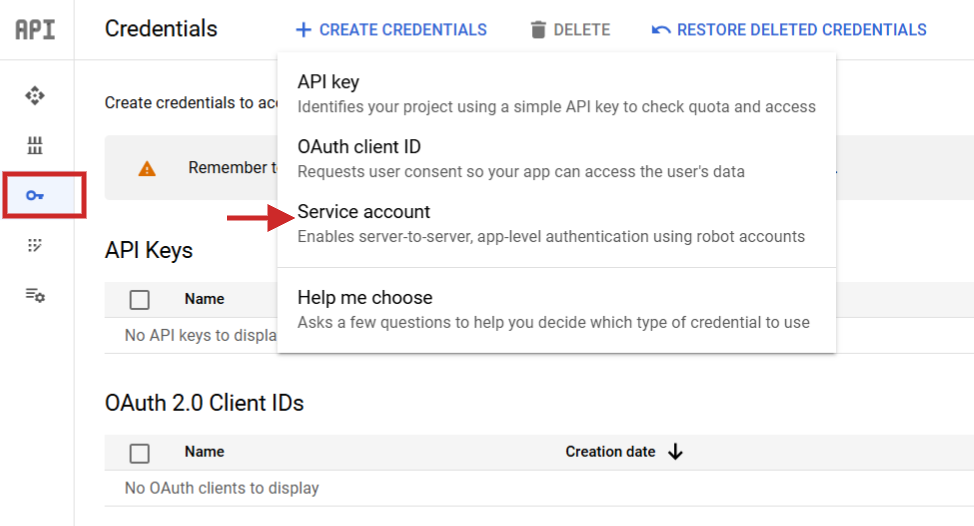
Step 1: Create a service account
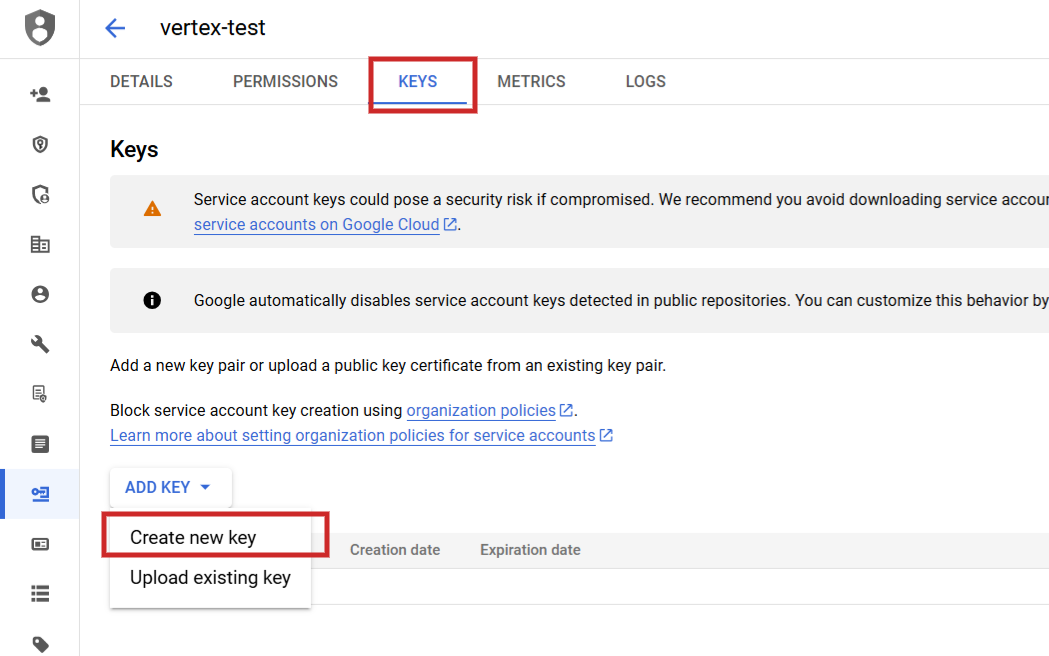
Step 2: Add a new key under the Service Account Keys tab

Step 3: Create a JSON key
Rename the JSON file to config.json and upload it (via the up arrow icon) to your Jupyter Notebook project folder.
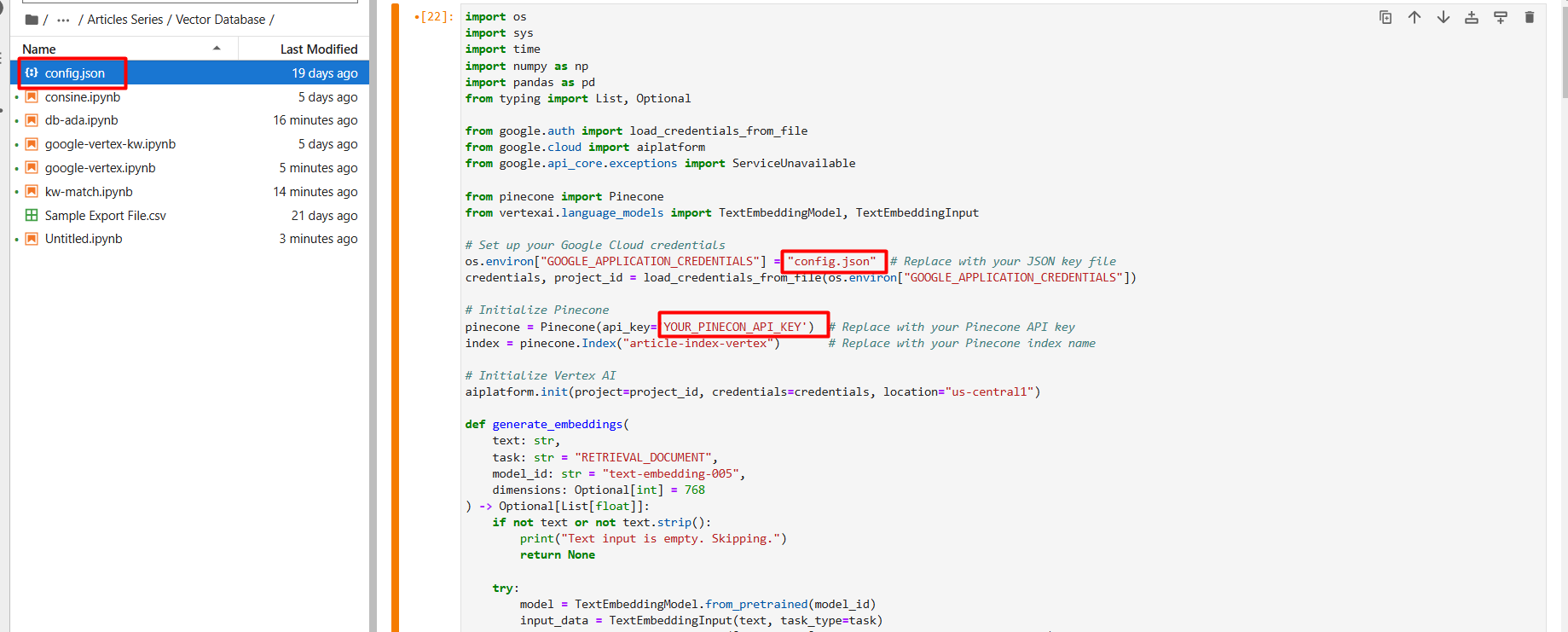 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024In the first setup step, create a new vector database named article-index-vertex by manually setting the dimension to 768.
Once built, you can run this script to start generating vector inserts from the same pattern file using Google Vertex AI text-embedding-005 model (you can choose text-multilingual-embedding-002 if you have non-English text).
import os
import sys
import time
import numpy as np
import pandas as pd
from typing import List, Optional
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import ServiceUnavailable
from pinecone import Pinecone
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Set up your Google Cloud credentials
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Replace with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Replace with your Pinecone API key
index = pinecone.Index("article-index-vertex") # Replace with your Pinecone index name
# Initialize Vertex AI
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
task: str = "RETRIEVAL_DOCUMENT",
model_id: str = "text-embedding-005",
dimensions: Optional[int] = 768
) -> Optional[List[float]]:
if not text or not text.strip():
print("Text input is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
input_data = TextEmbeddingInput(text, task_type=task)
vectors = model.get_embeddings([input_data], output_dimensionality=dimensions)
return vectors[0].values
except ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
# Load data from CSV
data = pd.read_csv("Sample Export File.csv") # Replace with your CSV file path
for idx, row in data.iterrows():
try:
permalink = str(row["Permalink"])
content = row["Content"]
embedding = generate_embeddings(content)
if not embedding:
print(f"Skipping article ID {row['ID']} due to empty or failed embedding.")
continue
print(f"Embedding for {permalink}: {embedding[:5]}...")
sys.stdout.flush()
index.upsert(vectors=[
(
permalink,
embedding,
{
'category': row['Category'],
'title': row['Title'],
'publish_date': row['Publish Date'],
'type': row['Type'],
'publish_year': row['Publish Year']
}
)
])
time.sleep(1) # Optional: Sleep to avoid rate limits
except Exception as e:
print(f"Error processing article ID {row['ID']}: {e}")
print("All embeddings are stored in the vector database.")
You will see below in the records of the insertions created.
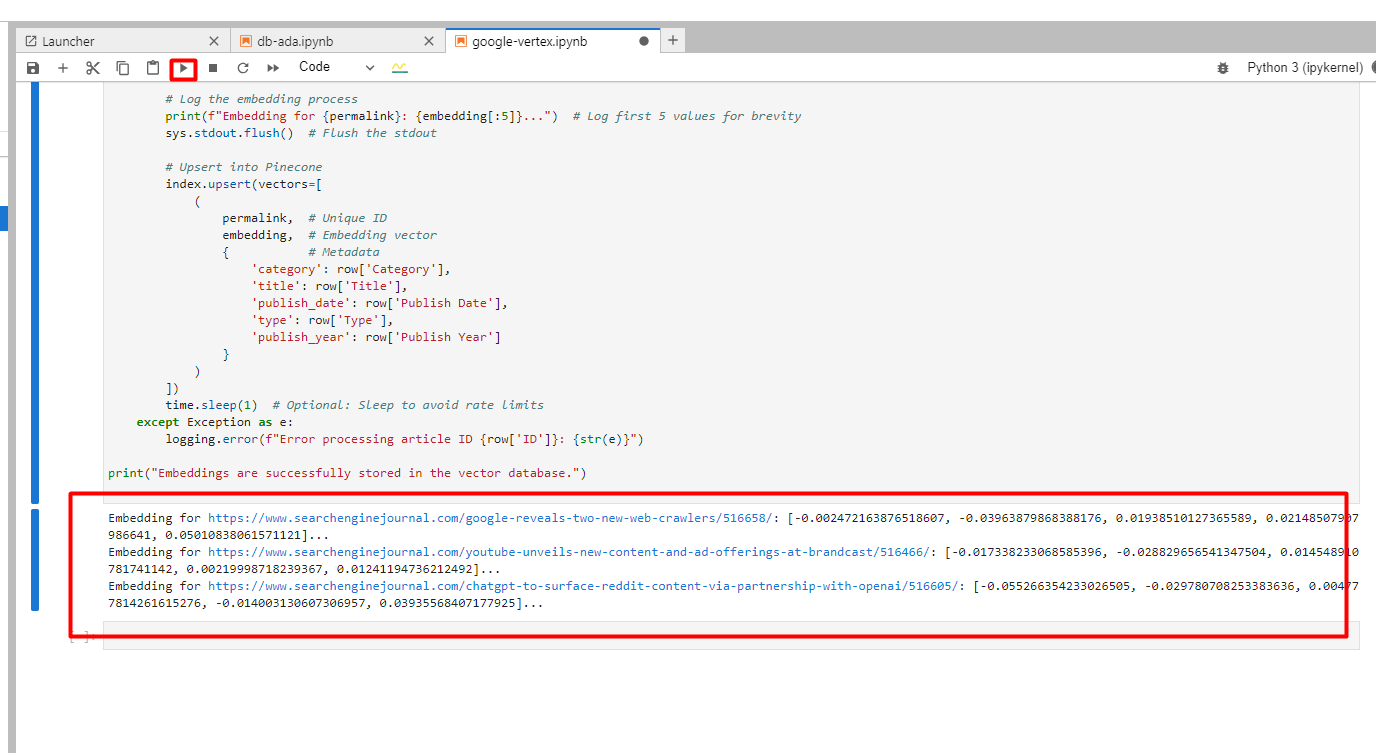 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024Now let’s do the same keyword matching with Vertex AI. There is a slight nuance as you need to use ‘RETRIEVAL_QUERY’ vs ‘RETRIEVAL_DOCUMENT’ as an argument when generating keyword inserts as we try to search for the article (aka document) that best matches our phrase.
Types of tasks are one of the important advantages that Vertex AI has over OpenAI models.
It ensures embeds capture keyword intent which is important for internal linking and improves the relevance and accuracy of matches found in your vector database.
Use this script to concatenate keywords with vectors.
import os
import pandas as pd
from google.cloud import aiplatform
from google.auth import load_credentials_from_file
from google.api_core.exceptions import ServiceUnavailable
from vertexai.language_models import TextEmbeddingModel
from pinecone import Pinecone
from tabulate import tabulate # For table formatting
# Set up your Google Cloud credentials
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Replace with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone client
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Add your Pinecone API key
index_name = "article-index-vertex" # Replace with your Pinecone index name
index = pinecone.Index(index_name)
# Initialize Vertex AI
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
model_id: str = "text-embedding-005"
) -> list:
"""
Generates embeddings for the input text using Google Vertex AI's embedding model.
Returns None if text is empty or an error occurs.
"""
if not text or not text.strip():
print("Text input is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
vector = model.get_embeddings([text]) # Removed 'task_type' and 'output_dimensionality'
return vector[0].values
except ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
def match_keywords_to_index(keywords):
"""
Matches a list of keyword-category pairs to the closest articles in the Pinecone index,
filtering by metadata if specified.
"""
results = []
for keyword_pair in keywords:
keyword = keyword_pair[0]
category = keyword_pair[1]
try:
keyword_vector = generate_embeddings(keyword)
if not keyword_vector:
print(f"No embedding generated for keyword '{keyword}' in category '{category}'.")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error/Empty',
'Title': 'No match',
'URL': 'N/A'
})
continue
query_results = index.query(
vector=keyword_vector,
top_k=1,
include_metadata=True,
filter={"category": category}
)
if query_results['matches']:
closest_match = query_results['matches'][0]
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': f"{closest_match['score']:.2f}",
'Title': closest_match['metadata'].get('title', 'N/A'),
'URL': closest_match['id']
})
else:
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
except Exception as e:
print(f"Error processing keyword '{keyword}' with category '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return results
# Example usage:
keywords = [["SEO Tools", "Tools"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]]
matches = match_keywords_to_index(keywords)
# Display the results in a table
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
And you will see the generated results:
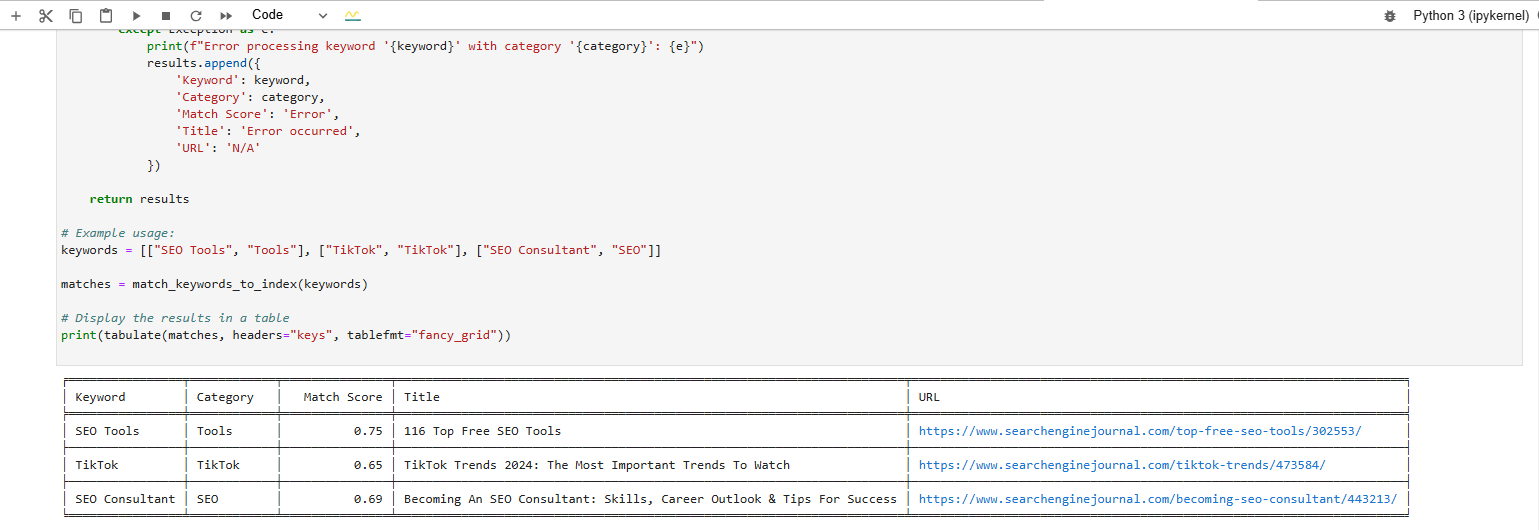 Keyword match results produced by the Vertex AI text embedding model
Keyword match results produced by the Vertex AI text embedding modelThink of this as a simplified (broad) way to check how semantically similar your writing is to the head keyword. Create a vector embedding of your own keyword head and entire article content via Google’s Vertex AI and calculate cosine similarity.
If your text is too long, consider implementing it fragmentation strategies.
A result close (cosine similarity) to 1.0 (like 0.8 or 0.7) means you are pretty close on that topic. If your score is lower, you may find that an intro that’s too long and has a lot of fluff can dilute relevance, and cutting it down helps increase it.
But remember, any changes should make sense from both an editorial and user experience perspective.
You can even do a quick comparison by embedding a competitor’s highly ranked content and see how you stack up.
This helps you more accurately match your content to your target topic, which can help you rank better.
There are already tools that perform such tasksbut learning these skills means you can take a customized approach tailored to your needs—and, of course, do it for free.
Experimenting yourself and learning these skills will help you get ahead with AI SEO and make informed decisions.
As additional reading, I recommend diving into these great articles:
More resources:
Featured Image: Aozorastock/Shutterstock



